VPteam 神经网络任务 - 1
Task-1
训练⼀个⽹络识别⼿写数字
Task-2
利⽤BASNet将VPteam Python 问题中的所有图⽚转化为显著性图⽚
Solution-1
对于这个问题,其实在《PyTorch深度学习实践》完结合集这个教程中,前10章主要就是对于MINST数据集的训练,这个教程中的所有代码都放置在仓库中了,对于这个题目可以使用第10章的代码
首先我们先回顾一下这个课程中讲到构建神经网络的基本流程:
- Prepare Dataset - 准备数据集
- Define Model - 定义模型
- Define Loss and Optimizer - 定义损失函数和优化器
- Train the Model - 训练模型
完整的代码将会放置在仓库中。
对于大部分内容其实不太需要说,核心是在模型的定义与训练上,接下来我们先回顾一些比较重要的概念。
Inception模块 是GoogleNet(也叫Inception V1)提出的一种创新网络结构,主要用于解决较深网络中的计算资源浪费和表征能力不足的问题。我来详细解释一下Inception模块的设计思路和工作原理:
-
启发思想
传统卷积神经网络每一层都使用相同大小的卷积核,但实际上不同大小的卷积核能够有效地提取不同尺度的特征。Inception模块设计的出发点就是在同一层使用多种不同尺度的卷积核,以增强网络的表征能力。 -
核心结构
Inception模块由多个并行的卷积通路组成。典型的Inception模块包含1x1、3x3、5x5卷积核以及3x3最大池化层,每个通路输出的特征映射在最后拼接在一起作为该模块的输出。 -
1x1卷积
1x1卷积在Inception模块中的作用是降维,即先使用1x1卷积减少输入特征映射的通道数,再进行3x3或5x5等卷积运算,从而大大减少了计算量和模型参数。 -
分解卷积
为进一步减少计算量,Inception也使用了分解卷积的技巧。比如先进行1x3和3x1的卷积替代3x3卷积,先进行1x5和5x1的卷积替代5x5卷积,降低了参数和计算量。 -
多级结构
在GoogleNet中,多个这样的Inception模块串联堆叠,形成网络的主干结构。不同级别的Inception模块可以使用不同的卷积核组合。 -
优势
Inception模块通过并行的多尺度卷积和分解卷积大大提高了网络的表征能力,同时也有效地控制了计算复杂度和模型参数。因此GoogleNet相比AlexNet等早期网络在同等精度下模型参数大幅减少,是卷积神经网络发展的一个重要里程碑。
Inception模块的设计理念影响了后续很多优秀卷积神经网络结构,体现了"多尺度、分解、并行"等思想,引领了神经网络结构设计的新潮流。
卷积(Convolution)
- 卷积是卷积神经网络的核心运算,它可以从输入数据(如图像)中提取出局部特征。
- 卷积的运算过程是:一个小的卷积核(kernel,也叫滤波器filter)在输入数据上滑动,对核窗口覆盖的区域做点积操作,得到输出特征映射。
- 通过设置不同的卷积核,可以提取输入数据的不同特征,如边缘、纹理、颜色等。
- 卷积核的权重在训练过程中不断学习调整,以获取最优特征。
- 卷积运算保留了输入数据的局部空间关系,这使得卷积层能捕获数据的空间局部相关性。
- 通过堆叠多层卷积层,可以逐步提取出更加抽象和复杂的特征表示。
池化(Pooling)
- 池化是对卷积后的特征映射进行下采样(dimension reduction),降低数据量的一种操作。
- 最常用的是最大池化(max pooling),就是在池化窗口内取最大值作为输出特征。
- 池化的主要作用是:
a. 减小特征的维度,降低后续计算量;
b. 实现平移不变性(translation invariance),使得特征对于小的平移保持稳定。 - 池化使特征映射对局部扰动不那么敏感,提高了数据的鲁棱性和空间不变性。
- 池化降低了维度同时也能够保留重要的特征信息,但池化操作也可能丢失一些细节信息。
两者结合使得卷积神经网络能够高效地从原始数据(如图像)中学习层次化、越来越抽象的特征表示,帮助下游任务(如分类、检测)取得好的效果。合理利用卷积和池化是设计卷积网络的关键。
那么我们的一个主要网络就是这样:
1 | class Net(torch.nn.Module): |
这个模型就是一个简单的CNN模型,包含两个卷积层和一个全连接层,每个卷积输出后再加上一个Inception模块。
训练的代码也是比较简单的:
1 | def train(epoch: int): |
下面则是一个比较通用的测试函数,用于在训练结束后对模型进行测试:
1 | def test_model(model, test_dir, device): |
分类器基本上都可以用这个代码,可以测试指定文件夹内的图片,并显示预测结果。
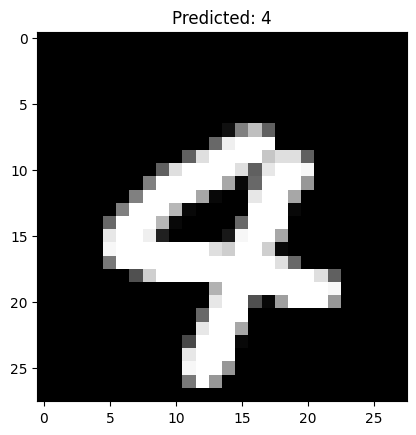
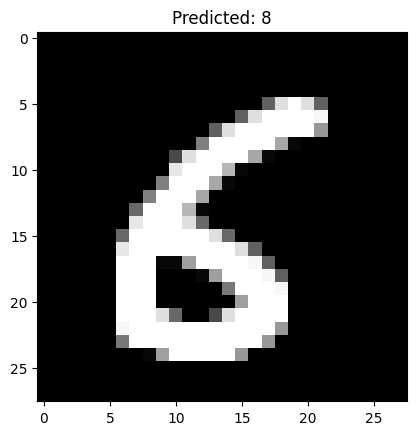
下面是我运行的一部分结构,可以看到除了把6预测成8,其他数字是正确的。
Solution-2
对于这个问题,其实BASNet仓库中的basnet_test.py已经基本实现了需要的功能,只要小作修改即可。
基本库的导入和两个基础函数都大差不差,不过我对save_output()函数做了一些小修改:
1 | def save_output(image_path: str, pred, output_dir=join(".", "output")): |
还有一些其他的一些小修改就是:
- 使用
os.path.sep来代替原来写死的/,避免在Windows上的错误。 - 利用
d1, *_ = net(inputs)这种写法,避免了多余的变量名。
运行仓库里的Jupyter Notebook,就可以得到结果啦~

虽然结果有点一言难尽()